

Reddit vs. crawlery – analiza robots.txt
Dziś postanowiłem przyjrzeć się plikowi robots.txt na Reddit i odkryłem coś interesujacego – serwis zablokował dostęp wszystkim crawlerom. Tak wygląda plik robots
# Welcome to Reddit's robots.txt
# Reddit believes in an open internet, but not the misuse of public content.
# See https://support.reddithelp.com/hc/en-us/articles/26410290525844-Public-Content-Policy Reddit's Public Content Policy for access and use restrictions to Reddit content.
# See https://www.reddit.com/r/reddit4researchers/ for details on how Reddit continues to support research and non-commercial use.
# policy: https://support.reddithelp.com/hc/en-us/articles/26410290525844-Public-Content-Policy
User-agent: *
Disallow: /
ale pamięć podręczna Google ze wczoraj, czyli 25 sierpnia 2024 godziny 22:43:45 pokazuje całkowicie inną wersję:
Zobacz plik robots.txt Reddit z dnia 25 sierpnia 2024
# Our robots.txt is for search engines
# 80legs
User-agent: 008
Disallow: /
# 80legs' new crawler
User-agent: voltron
Disallow: /
User-Agent: bender
Disallow: /my_shiny_metal_ass
User-Agent: Gort
Disallow: /earth
User-agent: MJ12bot
Disallow: /
User-agent: PiplBot
Disallow: /
User-Agent: *
Disallow: /*.json
Disallow: /*.json-compact
Disallow: /*.json-html
Disallow: /*.xml
Disallow: /*.rss
Allow: /r/*.rss
Disallow: /r/*/search.rss
Disallow: /r/*/comments/*.rss
Disallow: /r/*/config/*.rss
Disallow: /r/*/wiki/*.rss
Disallow: /*.i
Disallow: /*.embed
Disallow: /*/comments/*?*sort=
Disallow: */comment/*
Allow: /r/*/comments/*/*/de/*
Allow: /r/*/comments/*/*/es/*
Allow: /r/*/comments/*/*/fr/*
Allow: /r/*/comments/*/*/pt/*
Allow: /r/*/comments/*/*/it/*
Disallow: /r/*/comments/*/*/*/*
Disallow: /r/*/submit$
Disallow: /r/*/submit/$
Disallow: /message/compose*
Disallow: /api
Disallow: /post
Disallow: /submit
Disallow: /goto
Disallow: /*before=
Disallow: /user/*after=
Disallow: /u/*after=
Disallow: /domain/*t=
Disallow: /login
Disallow: /remove_email/t2_*
Disallow: /r/*/user/
Disallow: /gold?
Disallow: /search$
Disallow: /search?q=
Disallow: /search?title=
Disallow: /search/
Disallow: /*/search?
Disallow: /*/search/?
Disallow: /*/search$
Disallow: /*/search/$
Disallow: /search.compact$
Disallow: /*/search.compact$
Allow: /r/*/comments/*/search/$
Allow: /r/*/comments/*/search$
Disallow: /static/button/button1.js
Disallow: /static/button/button1.html
Disallow: /static/button/button2.html
Disallow: /static/button/button3.html
Disallow: /subreddits/*
Disallow: /buttonlite.js
Disallow: /timings/perf
Disallow: /counters/client-screenview
Disallow: /*?*feed=
Disallow: /svc/shreddit/*
Disallow: /svc/sh/*
Disallow: /svc/web/*
Disallow: /graphql
Disallow: /errors$
Disallow: /live/*
Disallow: /mediaembed/*
Disallow: /media
Allow: /
Allow: /sitemaps/*.xml
Allow: /posts/*Zapisany cache: w archive.org, archive.is
Temat o tyle mnie zainteresował, że stosunkowo nie dawno, bo miesiąc temu seroundtable.com poinformowało, że Reddit zablokował wyszukiwarkę Bing i inne, ale nie Google. Teraz jednak Reddit postanowił zablokować dostęp wszystkim robotom(???).
Dyrektywa site:reddit.com zwraca
- Około 355 000 000 wyników (0,46 s) w google.com
- Około 1 960 000 w bing.com
- Yandex, DuckDuckGo czy Seznam też jeszcze wyświetla wyniki dla Reddit
Narzędzia Google i archive.org
Internet Archive skanuje robots reddita aż miło – dziennie po 200-300 razy i jest identyczny, co dla operatora cache, czy testu wyników z elementami rozszerzonymi od Google.
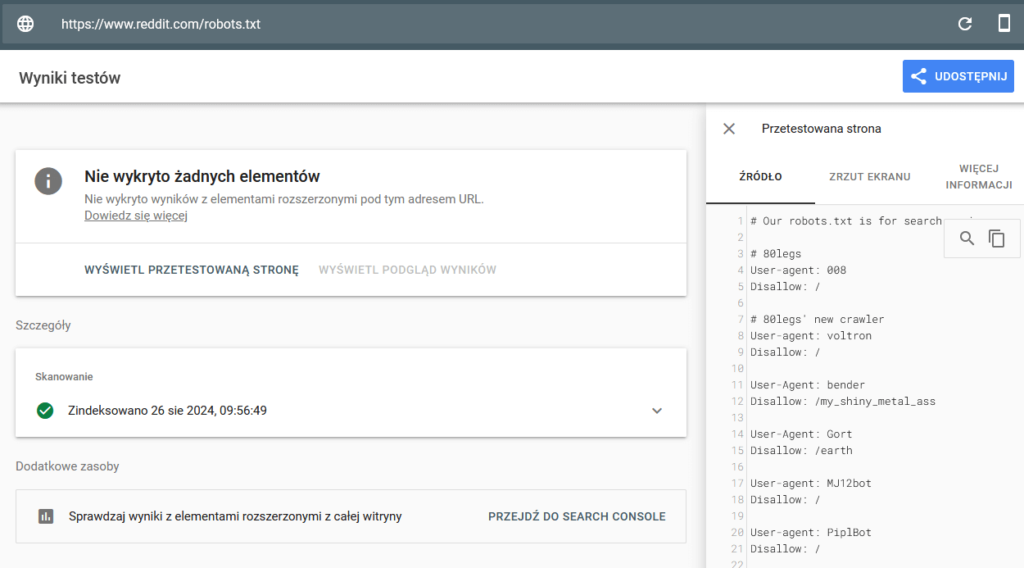
Bing nadal blokowany
Sprawdziłem też narzędziem mobile friendly test od bing’a i tutaj nie ma zaskoczenia. Bing nadal blokowany.
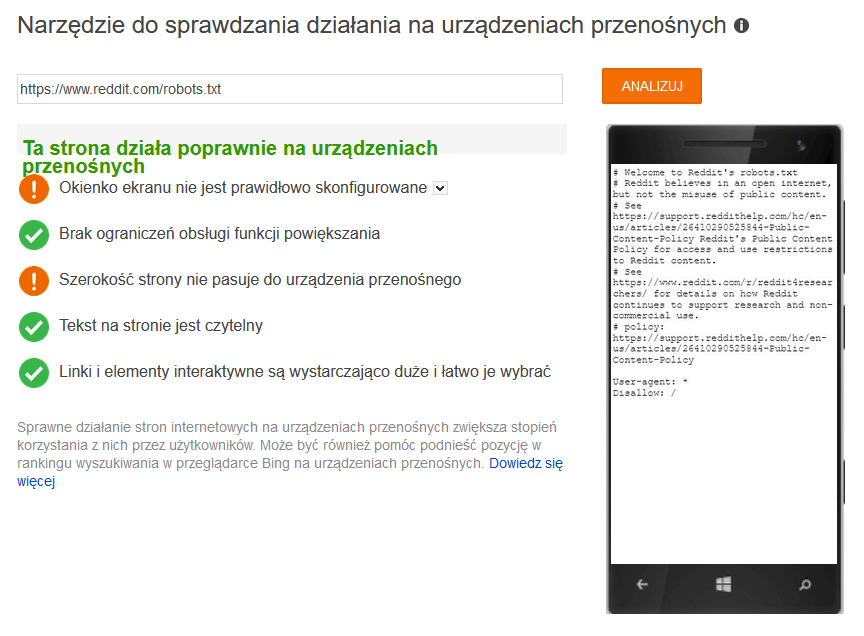
Wyjaśnienie
Myślę że Reddit swój robots.txt wyświetla wszystkim z dyrektywą Disallow: / jako domyślny, a wyjątkiem od tej reguły jest Google i niekomercyjne projekty jak archive.org (Internet Archive). Na blogu reddita można też przeczytać:
badacze i organizacje, takie jak Internet Archive, będą nadal mieć dostęp do treści Reddit dla celów niekomercyjnych.
Wygląda na to, że twórcy reddit.com korzystają z typowego cloakingu (wyświetlanie różnych treści różnym użytkownikom lub robotom). Ciekawe rzeczy się dzieją, a jeszcze nie dawno informowałem jak John Mueller ukrył robots.txt w pliku audio przy pomocy steganografii 😀
Pozdrawiam