

JavaScript SEO – przewodnik
JavaScript SEO to działania i techniki optymalizacji stron internetowych, które mają na celu poprawę widoczności i skanowania treści generowanych za pomocą języka programowania JavaScript w wyszukiwarkach. Polega to na dostosowywaniu kodu, struktury i zawartości strony tak, aby roboty indeksujące mogły bez problemów odczytać i zrozumieć treść wyświetlaną przez przeglądarki internetowe. JavaScript SEO jest szczególnie istotne w przypadku stron typu Single Page Application (SPA), które w dużej mierze opierają się na tym języku. JavaScript (js) to jeden z najważniejszych języków programowania w dzisiejszym świecie – JS jest używany po stronie klienta w 98,9% wszystkich stron internetowych, ale co to właściwie jest JavaScript i dlaczego powinieneś o nim wiedzieć więcej jeżeli robisz w SEO?
Co to jest JavaScript?
JavaScript jest językiem skryptowym i nie jest bezpośrednio rozumiany przez komputer, ale przeglądarki mają wbudowany silnik JavaScript, który pomaga im zrozumieć i zinterpretować kod. Silniki te konwertują js na język zrozumiały dla komputera. Czyli silnik JavaScript jest komponentem przeglądarki, który odpowiada za analizę, kompilację i wykonanie kodu JavaScript.
| Przeglądarka | Silnik |
|---|---|
| Google Chrome (Chromium) | V8 |
| Firefox | SpiderMonkey |
| Edge | Chakra |
| Opera, Brave i mniej niszowe korzystają z Chromium | V8 |
Czym tak naprawdę różni się JavaScript od innych języków programowania? Oto mała analogia:
- HTML – dom w stanie surowym
- CSS – pomalowany, umeblowany
- JavaScript – wszystkie niezbędne udogodnienia, np. prąd 😉
To właśnie js w dużej mierze dodaje interaktywne funkcje do strony. Chyba każdy użytkownik internetu spotkał się ze stroną gdzie jest używany JavaScript, ale nie każdy jest tego świadomy. W sklepach internetowych magiczny przycisk “Kup teraz”, którym bez przeładowania strony dodajesz produkty do koszyka, przyciski typu “pokaż więcej” czy “załaduj więcej” na stronach, które bez przeładowania strony wyświetlają kolejne posty. To jest właśnie JavaScript – dynamiczne ładowanie treści, leniwe ładowanie (eng. lazy load) i różnego rodzaju efekty wizualne, animacje, walidacja formularzy, aplikacje, gry online, automatyzacja, skrypty w Google Docs, Sheets i Slides (tzw. Apps Script), etc.
Dzięki popularnym frameworkom i bibliotekom takim jak React, Angular czy Vue.js, programiści mogą tworzyć zaawansowane aplikacje internetowe z dynamicznym interfejsem użytkownika, które działają szybko i sprawnie, przypominając tradycyjne aplikacje desktopowe. Wieloplatformowe środowisko uruchomieniowe Node.js może być używane do tworzenia aplikacji serwerowych, narzędzi wiersza poleceń, a nawet aplikacji desktopowych. Mało tego obecnie gdy jest moda na AI, to js posiada biblioteki wspierające różne typy uczenia maszynowego. Od uniwersalnych bibliotek jak TensorFlow.js, przez sieci neuronowe takie jak BrainJS czy Keras.js, aż po przetwarzanie języka naturalnego. To znaczy, że js jest jak wszechstronny ninja – otwierasz lodówkę, a tam JavaScript 😀
Pomimo swojej elastyczności należy używać go z rozwagą, bo z drugiej strony roboty skanujące mają ciągle problemy z jego czytaniem. Proste skrypty są łatwe do renderowania, ale zaawansowane skrypty już tworzą problemy i może się skończyć na tym, że googlebot nie zaindeksuje treści, a co gorsze całej strony. Im więcej kodu js, tym więcej czasu roboty muszą przeznaczyć na zrozumienie po co ten kod jest w tym miejscu. Przekłada się to bezpośrednio na crawl budget.
Żeby odpowiedzieć na zadane pytanie w nagłówku “Jaki wpływ na SEO ma JavaScript?” najpierw trzeba zrozumieć jak wykonywany jest JavaScript na stronie, a następnie jak googlebot (bo na nim nam zależy) czyta JavaScript.
Wykonanie kodu JavaScript
Ogólnie trzeba całość podzielić na 4 kroki:
- Parsowanie czyli analiza składni (Parsing): Przed rozpoczęciem wykonania kodu przeglądarka analizuje składnię, aby zrozumieć jego strukturę. W tym kroku kod jest przetwarzany z surowego tekstu na strukturę danych, którą można łatwo interpretować.
- Kompilacja (Compilation): Po analizie składni kod jest tłumaczony na kod bajtowy (eng. bytecode).
- Wykonanie (Execution): Po skompilowaniu kod jest wykonywany linia po linii wykorzystując do tego interpreter i / lub kompilator. Wykonywane są operacje, funkcje są wywoływane, zmienne przypisywane itd. Proces kompilacji i wykonywania kodu idzie w parze.
- Optymalizacja (Optimization): W trakcie wykonania kodu, silniki JavaScript najpierw tworzy niezoptymalizowaną wersję bytecode, aby wykonanie kodu mogło rozpocząć się jak najszybciej. Jednak w tle kod jest optymalizowany podczas wykonywania już uruchomionego programu.

Jak googlebot renderuje JavaScript?
Googlebot przechodzi wieloetapowy proces skanowania, renderowania i indeksowania treści opartych na JavaScript. Cały proces jest rozbity na 3 główne kroki:
- Skanowanie (crawling): Googlebot pobiera adres URL z kolejki indeksowania i sprawdza robots.txt pod kątem możliwości crawlowania adresu. Jeżeli adres nie jest zabroniony dyrektywą disallow, to analizuje odpowiedź HTML i dodaje znalezione (ale dozwolone) adresy do kolejki indeksowania.
- Renderowanie (Rendering): Googlebot decyduje, które zasoby wymagają wyrenderowania głównej treści strony. Następnie używa headless Chrome (przeglądarka bez interfejsu graficznego z której korzysta googlebot) do renderowania strony i wykonywania kodu JavaScript. Ten proces renderowania jest obsługiwany przez Web Rendering Service (WRS) – kluczowy element całego procesu. WRS działa po przeczytaniu HTML ale przed wygenerowaniem drzewa DOM, które jest ostatecznie analizowane przez googlebota.
- Indeksowanie (Indexing): po wyrenderowaniu strony googlebot analizuje wyrenderowany kod HTML i wyodrębnia treść do zaindeksowania.
Strony, które zawierają duże ilości kodu JavaScript mają opóźnione indeksowanie, ponieważ js jest zasobożerny i z tego powodu googlebot dzieli crawlowanie na dwa etapy:
- 1 etap: googlebot skanuje cały kod HTML i umieszcza stronę w kolejce do renderowania przez WRS
- 2 etap: googlebot renderuje cały kod JavaScript w usłudze renderowania stron

Źródło obrazu: https://developers.google.com/search/docs/crawling-indexing/javascript/javascript-seo-basics?hl=pl
Ten dwuetapowy proces ma duży wpływ na crawl budget i powoduje opóźnienia w indeksowaniu treści opartych na JavaScript w porównaniu ze stronami zrobionymi stricte w HTML/CSS. Jednak nie jest równoznaczne z tym, że to trwa tylko raz. Właściwie cały proces dla adresu czy strony może być przetwarzany setki razy, a nawet więcej zanim dojdzie do skutku. Każdy musi być też świadomy, że powyższy opis jak i obraz są jedynie bardzo dużym uproszczeniem, bo nie wiemy co się dzieje w środku oraz ile systemów i czynników ma wpływ całość.
Budżet renderowania (render budget)
Ważne! Nie mylić z crawl budget! Mimo iż render budget i crawl budget są mocno skorelowane, to nie są identyczne.
Render budget to pojęcie odnoszące się do ograniczonej ilości zasobów, jaką robot (głównie googlebot) może przeznaczyć na wykonanie i wyrenderowanie JavaScript, HTML, CSS, JSON, a nawet XHR. Właściwie budżet renderowania odnosi się do wszelkich zasobów, które googlebot musi przetworzyć, aby w pełni wyrenderować stronę.
- Ważne: 100kB HTML ≠ 100kB JavaScript
Gdy strona zawiera dużo kodu JavaScript, to jej renderowanie może być czasochłonne i wymagać znacznie więcej mocy obliczeniowej, dlatego w celu zoptymalizowania zasobów robot z góry ma ustalony limit jaki może przeznaczyć dla konkretnej strony lub skryptu (co to jest error loops?). Jeśli strona przekroczy ustalony budżet renderowania, to niektóre elementy (treści, a nawet cała strona) mogą nie zostać wyrenderowane lub zostaną wyrenderowane ale nieprawidłowo, co może mieć negatywny wpływ na widoczność strony. Dlatego też optymalizacja budżetu renderowania – właściwie js jako najbardziej zasobożernego elementu strony – jest całkiem ważnym aspektem.
W skrócie:
- render budget – zasoby i moc obliczeniowa robota potrzebna do wyrenderowania strony
- crawl budget – zasoby i możliwości serwera, na którym stoi strona. Oczywiście tylko w tym konkretnym przypadku, bo na crawl budget składa się o wiele więcej czynników niż tylko wydajność serwera
Co to jest Client-Side Rendering (CSR)
Client-side Rendering (CSR) odnosi się do procesu renderowania strony internetowej po stronie klienta, czyli w przeglądarce użytkownika. Serwer dostarcza jedynie minimalny zestaw zasobów HTML, CSS i JavaScript, a cała reszta zawartości jest renderowana dynamicznie w przeglądarce po pobraniu kodu JavaScript. W takim razie przeogromną zaletą CSR jest to, że serwer nie musi generować pełnej struktury HTML dla każdego żądania, co może znacząco obniżyć obciążenie serwera. Mimo to czy strona działa wydajnie zależy też od wielu innych czynników.
Roboty wyszukiwarek (np. googlebot, bingbot) nie wchodzą w interakcję jak człowiek, czyli nie klikają w linki i “nie widzą” treści załadowanych dynamicznie, to jest jednym z głównych problemów w kontekście JavaScript SEO. Jednak ten problem można “załagodzić” przez użycie technik takich jak prerendering lub dynamiczne renderowanie:
- Prerendering polega na generowaniu statycznych wersji stron przed ich udostępnieniem
- Dynamiczne renderowanie polega na dostarczaniu robotom wyszukiwarek statycznej wersji strony, podczas gdy użytkownicy nadal otrzymują dynamiczną wersję
Z pomocą może przyjść płatne rozwiązanie prerender.io lub jedno z dwóch open-source
- Rendertron (GitHub)
- Puppeter (dokumentacja Google)
| Zalety | Wady |
|---|---|
| Serwer dostarcza tylko minimalne zasoby, co zmniejsza jego obciążenie | Pierwsze załadowanie strony jest wolniejsze ze względu, że przeglądarka musi pobrać i uruchomić kod JavaScript przed wyświetleniem treści |
| Ładowanie dynamicznych treści bez konieczności przeładowywania całej strony | Roboty takie jak googlebot czy bingbot nie widzą treści załadowanych dynamicznie, więc nie mogą skanować nowo załadowanych linków |
| Strona może ładować komponenty asynchronicznie. Skutkuje tym, że dany komponent jest ładowany tylko w momencie gdy jest potrzebny | Starsze przeglądarki mogą mieć problemy z obsługą zaawansowanych funkcji JavaScript, np. Opera Mini czy Internet Explorer 11 |
| Jeśli kod nie jest odpowiednio zabezpieczony lub jest dziurawy, to może być podatny na ataki, np. XSS (Cross-site scripting) |
Przykłady kiedy korzystać z Client-Side Rendering
Strony, które wymagają dynamicznej aktualizacji danych po załadowaniu:
- Single Page Application (SPA) – aplikacja jednostronicowa
- Narzędzia online typu: edytor dokumentów, edytor graficzny (photoshop online)
Treści dostępne po zalogowaniu, gdzie googlebot nie ma, nie powinien mieć dostępu lub treści są multimedialne:
- Wszelkie dostępy po zalogowaniu
- koszyk w sklepie
- powiadomienia
- Panel reklamodawcy
- Narzędzia analityczne
- Narzędzia CRM
- Platformy edukacyjne
- Platformy multimedialne (youtube, twitch)
Co to jest Server-Side Rendering (SSR)
Server-Side Rendering (SSR) to technika renderowania strony na serwerze, a następnie wysyłania w pełni wyrenderowanej strony HTML do przeglądarki klienta. Przeglądarka wyświetla stronę, bez konieczności oczekiwania na wysłanie dodatkowych żądań do serwera lub wykonanie JavaScriptu.
SSR może być korzystne dla JS SEO, ponieważ roboty wyszukiwarek mogą z łatwością analizować i indeksować w pełni wyrenderowany kod HTML, który obejmuje całą treść. Skutkuje to tym, że roboty nie muszą przeznaczać kolejnych zasobów na zrozumienie “po co tutaj jest ten javascript”. Dodatkowo SSR poprawia ogólną wydajność Core Web Vitals (CWV) z naciskiem na First Contentful Paint (FCP) oraz Time to Interactive (TTI).
Niestety ale zalety tego rozwiązania, to nie wszystko. Server-Side Rendering jak każde inne rozwiązanie ma również wady, o których trzeba wspomnieć. Chyba najważniejszą jest większe obciążenie serwera, ponieważ to serwer odpowiada za renderowanie strony, a nie przeglądarka odwiedzającego.
| Zalety | Wady |
|---|---|
| Zdecydowanie lepsze dla robotów | Możliwy dłuższy czas odpowiedzi serwera (TTFB) |
| Cała strona jest wyrenderowania w HTML | Możliwy dłuższy czas ładowania strony |
| Szybsze pierwsze wyświetlenie | Zwiększone obciążenie, więc wymaga wydajniejszego (mocniejszego) serwera |
| Lepsza kompatybilność z przeglądarkami wliczając te stare | Problem z elementami, które wymagają częstego odświeżania zawartości |
Przykłady kiedy korzystać z SSR
- Blogi
- Sklepy
- Portale informacyjne
- Landing pages
- Portfolio
Dynamiczne renderowanie czyli CSR + SSR
Dynamiczne renderowanie to połączenie dwóch poprzednich technik. W zależności od wysłanego żądania (klient czy robot) – CSR wyświetla interaktywną stronę dla klienta, a SSR wyświetla statyczną wersję strony przyjazną dla robotów. Dzięki takiemu hybrydowemu podejściu można zyskać najwięcej korzyści. W takim razie jest “wilk syty i owca cała“. Najprościej można to przedstawić w postaci poniższego obrazu:

Uwaga! bardzo istotną kwestią jest, że SSR nie może być używane jako uniwersalne rozwiązanie do renderowania. Jeżeli korzystasz lub zamierzać korzystać z renderowania po stronie serwera, to koniecznie powinieneś zwrócić uwagę na to jak wygląda wersja statyczna twojej strony, a dokładniej czy jest aktualna, no bo co ze strony statycznej, która się nie odświeża i wyświetla stare treści?
Jak google “widzi” strony
Skoro wytłumaczyłem podstawy takie jak wykonywanie js oraz jak googlebot renderuje javascript na stronie. Dobrze będzie zrozumieć jak googlebot “widzi” stronę. Minusem treści ładowanych dynamicznie jest fakt, że googlebot oraz inne roboty ich “nie widzą”.
Dlaczego roboty indeksujące mają trudności z dynamicznie ładowanymi treściami? Ponieważ takie treści wymagają wykonania JavaScriptu, właściwie tutaj wykorzystuje się AJAX, czyli asynchroniczny JavaScript i XML. Treści dynamiczne ładowane są asynchronicznie, więc pojawiają się dopiero w pewnych okolicznościach (np. klikniecie lub zjechanie do pewnego poziomu strony) i nie są załadowane do źródła od razu wraz z wejściem na stronę, a “doklejane” później bez przeładowania tejże strony. Skoro roboty nie widzą tych treści = nie ma bezpośredniego linku, więc z miejsca zdolność skanowania robotów jest ograniczona. Mimo iż pozytywnie wpływa na bounce rate!
Metoda 1: Sprawdź źródło strony
Najszybszy sposób na sprawdzenie co roboty mogą zobaczyć, bo googlebot i inne roboty nie korzystają z GUI (graficzny interfejs). Wystarczy odpalić źródło strony by mieć namiastkę informacji. Tutaj są 3 możliwości:
- Do paska adresu dopisać view-source:
- Nacisnąć na klawiaturze kombinację klawiszy CTRL + U
- Prawym przyciskiem myszy odpalić menu kontekstowe i wybrać coś w stylu “Pokaż źródło strony“
Metoda 2: Narzędzia developera w przeglądarce
Każdy WebDeveloper zna DevTools w przeglądarce. Przeglądanie kodu i jego modyfikacja w czasie rzeczywistym bez faktycznej ingerencji jest super wygodnym rozwiązaniem. Wszystko co zrobisz jest lokalnie, a po odświeżeniu strony zmiany wracają, bo realnie nie były wprowadzone na stronie.
Klawisz F12 jest najszybszą opcją dostania się do devtools ale można też skorzystać ze skrótu klawiszowego CTRL + SHIFT + I 🙂
- Chrome DevTools: https://developer.chrome.com/docs/devtools?hl=pl
- Firefox DevTools: https://firefox-dev.tools/
Metoda 3: Narzędzie do sprawdzania adresów URL (URL Inspection tool) w Google Search Console
Najlepszym narzędziem dla twojej strony i prawdziwym przyjacielem jest Google Search Console. Jeśli googlebot będzie miał problemy ze stroną, znajdziesz tam wszystkie potrzebne informacje. Dlatego odsyłam cię bezpośrednio do całkiem obszernej dokumentacji narzędzia do sprawdzania adresów URL.
Metoda 4: Test wyników z elementami rozszerzonymi
Generalnie to narzędzie służy do testowania stron pod kątem prawidłowej implementacji elementów rozszerzonych (rich snippets). To właśnie dzięki temu można zobaczyć, np. oceny w postaci gwiazdek. Jednak ma też bardzo ogromną zaletę, pokazuje identycznie jak w powyższej metodzie stronę. W taki sposób można sprawdzić stronę konkurencji 😉
- Link do narzędzia: https://search.google.com/test/rich-results
Ciekawostka: Rich Results Test obsługuje maksymalnie 5 przekierowań. Opisałem to w moim Case Study: Długość łańcucha przekierowań dla narzędzi i robotów.
Linki w javascript
Fundamentem stron są linki, więc ich prawidłowa implementacja jest kluczowa dla robotów. Z tym nie można dyskutować, bo cały internet na tym się opiera, dlatego najlepsze – co można zrobić w tej kwestii – są linki w HTML, czyli klasycznie <a href>. Dlaczego warto zadbać o możliwość skanowania linków na stronie?
- Linki po których googlebot (i inne roboty) może “chodzić” przyczyniają się do lepszego pozycjonowania
- Wtedy roboty mogą lepiej zrozumieć strukturę strony i powiązania między różnymi podstronami (linkowanie wewnętrzne, linkowanie do arkuszy styli, czy javascript) czy linkowaniem do zewnętrznych stron lub źródeł (linkowanie zewnętrzne)
- W takim razie ułatwienie pracy robotom może tylko pomóc w zaindeksowaniu strony, a prawidłowe oznaczenie linków (np. przez inny kolor, czy podkreślenie) wpływa pozytywnie na UX (user experience), co jak uważam jest jednym z tysięcy czynników rankingowych.
Najlepsze praktyki tworzenia linków
Googlebot nie ma problemów z takimi linkami, ponieważ zawierają element <a> z atrybutem href
| Link bezwzględny – zawiera pełny adres url | <a href=”https://seekio.pl”> |
| Link względny – wskazuje na zasób znajdujący się w tej samej domenie. | <a href=”/seo/”> |
| Link JavaScript z atrybutem href | <a href=”/seo/” onclick=”javascript:goTo(‘seo’)”> |
| Link z klasą CSS | <a href=”/seo/” class=”klasa-CSS”> |
Googlebot może mieć problem z linkami ale i tak będzie próbował je przeanalizować, bo nadal znajduje się link (bez)względny
| Link z aplikacji Angular | <a routerLink=”seo”> |
| Link z funkcją JavaScript | <a onclick=”goto(‘https://seekio.pl’)”> |
Jak tworzyć “puste linki”
“Pusty link” nie zawiera żadnego adresu w atrybucie href. Pusty link można stworzyć na 3 sposoby:
- href=””
- href=”#”
- href=”javascript:void(0)”
Moim zdaniem najlepszą opcją jest numer 2, a najgorszą z możliwych, to href=”javascript:void(0)”, ponieważ przeglądarka ten pseudo-URL będzie starała się przetworzyć, w tym wszelkie roboty. Stosowanie takiego wynalazku jest całkowicie zbędne ze względów praktycznych jak i bezpieczeństwa!
Jaka jest różnica między href=””, a href=”#” ? Pierwszy załaduje ten sam adres, a drugi po prostu przeniesie natychmiastowo do góry. Można temu zapobiec tworząc link javascript z event.preventDefault()
<a href="#" onclick="event.preventDefault()">Do góry już nie przeniesie</a>Dodatkowo googlebot ignoruje linki z krzyżykami, więc to kolejny powód by korzystać z href=”#” całkowicie bezpiecznie 🙂
Ciekawostka: React ostrzega użytkowników przed użyciem href=”javascript:void(0)”
Warning: A future version of React will block javascript: URLs as a security precaution. Use event handlers instead if you can. If you need to generate unsafe HTML try using dangerouslySetInnerHTML instead. React was passed “javascript:void(0)”.
Ostrzeżenie w aplikacji React
Dynamiczne ładowanie treści (AJAX)
Odejdę od kwestii stritce technicznych, czas wyjaśnić co to znaczy, że treści na stronie ładują się dynamicznie, wliczając w to różne ale najpopularniejsze techniki. Jak wcześniej wspomniałem – minusem treści ładowanych dynamicznie jest fakt, że googlebot oraz inne roboty ich “nie widzą”. Jednym z kluczowych aspektów strony bazującej w dużej mierze na JavaScript jest dynamiczne ładowanie treści. Chodzi o wszystkie elementy, które bez przeładowania strony wyświetlają – dla przykładu – artykuły. Wystarczy nacisnąć przycisk “load more”, który wyświetli kilka(naście) kolejnych postów.
Robot crawlujacy nie przewija strony i nie klika w dosłownym tego znaczeniu, nie wchodzi w żadne interakcje na stronie, a jedynie parsuje treści. Stąd istotną kwestią jest pomóc robotom zrozumieć strukturę strony i pokazać “hej tutaj mam jeszcze inny link” przez stosowanie <a href>.
Paginacja
Fajną techniką jest tzw. “infinite scroll“, czyli nieskończone przewijanie. Bez żadnego klikania na stronie automatycznie pojawiają się kolejne treści. Z mojego doświadczenia wynika, że przyciski “pokaż więcej” czy technika infinite scroll bardzo pozytywnie wpływa na bounce rate. Jednak typowe “nieskończone ładowanie postów” nie jest przyjazne dla robotów. John Mueller stworzył infinity scroll z paginacją i uważam, że to jest świetne rozwiązanie. Przyjazne dla użytkownika i robotów, ponieważ w źródle strony są zapisane linki do poszczególnych stron.
Innym ale mocno podobnym do poprzednika jest “continuous scroll“. Polega to na tym, że treści są ładowane do pewnego momentu. Takie rozwiązanie ma wprowadzone np. spidersweb.pl w swoich artykułach. Przewija się 5 artykułów po czym kolejne artykuły nie są wyświetlane. W październiku 2021 Google dla wyszukiwarki mobilnej wprowadziło właśnie continuous scroll (źródło), a rok później dla urządzeń desktopowych w USA. Kiedy reszta świata dostała taką funkcję, to już nie mam pojęcia. Google pokazuje maksymalnie 6 stron wykorzystując opisaną technikę. Gdy wyłączyłem wykonywanie javascript w google.pl, to znika ajaxowe rozwiązanie na rzecz standardowej paginacji w html – polecam sprawdzić samemu!
Technika load more, infinite scroll czy continuos scroll na stronach kategorii i/lub stronie głównej może zastąpić paginację jednak wszystko zależy od objętej strategii pozycjonowania czy warto 🙂
Ciekawostka: znajomy po wprowadzeniu infinite scroll na stronie stwierdził, że zwiększyły mu się zarobki z AdSense.
Lazy loading
Przedostatnią techniką, którą często stosuje się na stronach internetowych jest “lazy loading“, czyli leniwe ładowanie. Polega to na załadowaniu elementów strony dopiero w momencie gdy użytkownik te treści może zobaczyć, np. reklamy, posty, obrazy, wideo, iframe. Najlepszym przykładem może być forum oparte o IPS (np. PiO). Opóźnienie ładowania elementów może wpłynąć pozytywnie na redukcję czasu ładowania strony, co generalnie rzutuje na cały Core Web Vitals (CWV). W WordPress 5.5 i wyższych wersjach zostało wprowadzone natywne lazy loading dla wszystkich obrazów (źródło).
Preloader
Jeszcze jedną techniką, która jest stosowana, a osobiście mnie irytuje jest preloader. To element, który za zadanie ma poinformować użytkownika o trwającym procesie ładowania strony. Jest to rodzaj wskaźnika postępu, który może przyjmować różne formy, takie jak animacja, pasek postępu lub ikona.
Najedź kursorem na szarą ramkę, żeby zobaczyć przykładowy preloaderTo rozwiązanie jest dobre jeśli czeka się na załadowanie pewnego elementu ale nie całej strony! Najbardziej uciążliwy jest preloader w momencie gdy strona ma źle ustawione cache’owanie albo minifikację js’a. Wtedy “ładowanie” trwa w nieskończoność i strona mimo pełnego załadowania nie wyświetla treści, ponieważ preloader nie znika, bo wyświetla się nad całą treścią. Obecnie osiągamy takie szybkości internetu, że to całkowicie zbędny dodatek (moim zdaniem).
Te kilka technik – razem lub osobno – sprawiają, że strony internetowe są interaktywne wpływając pozytywnie na UX ale nie zawsze pozytywnie na SEO.
Przekierowania w JS
Generalnie przekierowanie po stronie serwera powinno być robione ale nie zawsze jest taka możliwość. Poniżej przedstawiam listę zalet oraz wad:
Przekierowanie po stronie serwera
Zalety:
- Przekierowanie po stronie serwera (PHP / .htaccess) jest natychmiastowe i nie wymaga dodatkowych zasobów, ponieważ serwer wykonuje przekierowanie zanim strona zostanie załadowana do przeglądarki
- Patrząc pod kątem SEO, takie przekierowanie jest wydajniejsze
- Dodatkowo jest realizowane niezależnie od przeglądarki użytkownika czy innych czynników jak wyłączona obsługa javascript w przeglądarce
- Podczas skanowania strony googlebot od razu obsługuje przekierowanie po stronie serwera
Wad nie znam lub nie jestem ich świadomy 🙂
Przekierowanie JavaScript (po stronie klienta)
Zalety:
- Na pewno większa interaktywność jest dużym plusem, bo można kontrolować takie przekierowanie w zależności od zachowania czytelnika
- Ewentualnie po spełnieniu pewnych warunków
Wady:
- Standardowo – realizowane po stronie klienta dla robotów mogą nie być oczywiste. O ile goolebot jeszcze jakoś sobie radzi (wyparsowanie url / przetworzenie skryptu przy pomocy Web Rendering Service), tak inne roboty mogą mieć problem ze zrozumieniem albo wcale nie przetwarzać skryptów
- Pod kątem wydajności takie przekierowanie również nie jest dobre, bo przeglądarka musi je przetworzyć, a zrobi to dopiero po załadowaniu skryptu
- W kwestiach bezpieczeństwa: przekierowanie js jest podatne na manipulacje
- Dodatkowo można je bardzo łatwo ominąć. Wystarczy wyłączyć obsługę JavaScript
- Googlebot sprawdza przekierowanie w momencie renderowania strony, co wydłuża całą ścieżkę i ma negatywny wpływ na SEO
W skrócie
- Przekierowanie po stronie serwera: Wydajne i idealne dla robotów oraz do stałych zmian URL żeby zachować strukturę strony (3xx),
- Przekierowanie po stronie klienta: Dynamiczne zmiany w zależności od interakcji użytkownika, warunków przeglądarki oraz w aplikacjach SPA, gdzie nawigacja odbywa się bez pełnego odświeżania strony
Nie blokuj JavaScript w robots.txt
Uważam że każdy właściciel poważnej strony internetowej powinien wiedzieć co to jest plik robots.txt dlatego nie będę rozwodził się na ten temat. Jak korzystać z pliku robots.txt to całkiem inna kwestia.
Jest jedna niepisana zasada!
- nie blokuj javascript i arkusza styli w robots.txt
Jeżeli masz w swoim pliku robots dyrektywy typu:
Disallow: /css/
Disallow: /js/To koniecznie je usuń, ponieważ trzymanie tego jest idealną drogą do zaliczenia epic fail dla seo, a powodem jest stworzenie tzw. error loops!
Co to jest error loops?
Error loops powstaje w momencie zablokowania plików JavaScript (.js) i / lub arkuszy styli (.css) w robots.txt. Nie ważne czy to pojedyncze pliki, czy całe foldery. Powoduje to, że robot (np. googlebot) napotyka problem podczas crawlu strony. Bez dostępu do tych plików robot może “widzieć” stronę w inny sposób niż normalnie powinien, a dokładniej bez pełnego obrazu strony nie może w pełni zrozumieć jej wyglądu i całej funkcjonalności. Robot może wielokrotnie spróbować sprawdzić js i / lub css, bo ciągle trafia na te pliki, ale za każdym razem napotyka problem z brakiem dostępu. Po tak zmarnowanym budżecie renderowania, robot może w końcu zrezygnować z dalszych prób, a to jak najbardziej prowadzi do zmniejszona widoczności strony.
Jak emulować renderowanie JavaScript przy pomocy Screaming Frog
Aby jak najdokładniej emulować googlebota, silnik renderujący programu Screaming Frog korzysta z projektu Chromium. Co – trzeba zaznaczyć – nie jest jednoznaczne, że identycznie renderuje strony co googlebot. SF jest kompatybilny z systemem:
- Windows 10
- Windows 11
- Serwer Windows 2016
- Serwer Windows 2022
- Ubuntu 14.04+ (tylko 64-bitowy)
- macOS 11+
W celu emulacji renderowania javascript:
- Z menu wybierz Configuraton -> Spider -> Rendering
- Następnie otworzy się nowe okno i z rozwijanej listy wybierz: Rendering JavaScript
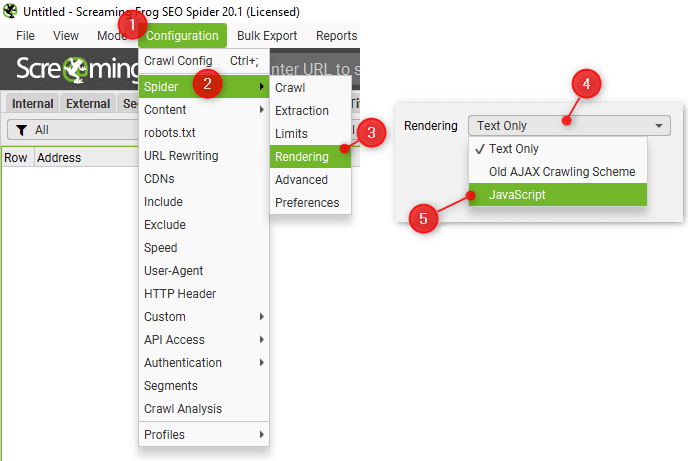
Ustawienia
- Enable Rendered Page Screenshots – tworzy zrzuty ekranu, które możesz przeglądać w zakładce “Rendered Page”, w dolnym menu. Ustawienie domyślnie włączone
- Enable JavaScript error reporting – włącza raportowanie błędów JavaScript w ramach odpowiednich filtrów na karcie „JavaScript”. Szczegółowe błędy, ostrzeżenia i problemy możesz wyświetlić w dolnym menu, w zakładce “Chrome Console Log”. Ustawienie domyślnie wyłączone
- Flatten Shadow DOM – googlebot może spłaszczyć i zindeksować zawartość Shadow DOM jako część renderowanego kodu HTML strony. Ustawienie domyślnie włączone
- Flatten iframes – googlebot wstawi osadzone ramki (iframes) do diva w wyrenderowanym HTML stronie nadrzędnej, jeśli warunki na to pozwalają. Obejmują one ustawienie wysokości, posiadanie widoku mobilnego oraz brak oznaczenia noindex. Ustawienie domyślnie włączone
- Enable Website Archive – SF pobierze i zapisze cały kod HTML oraz znalezione zasoby podczas skanowania, by zapisać wszystkie pliki lokalnie.
- AJAX Timeout – Ustawienie jak długo (w sekundach) Screaming Frog powinien umożliwiać wykonanie JavaScriptu przed rozważeniem załadowania strony. Ustawione domyślnie 5 sekund, jest to całkiem rozsądny czas.
- Window Size – Ustawia rozmiar widocznego obszaru, co można zobaczyć na zrzutach ekranu wyrenderowanej strony. Znajdziesz w dolnym menu, w zakładce “Rendered Page”
Podsumowania nie ma, bo ciąg dalszy nastąpi… ale już w innym formacie 🙂